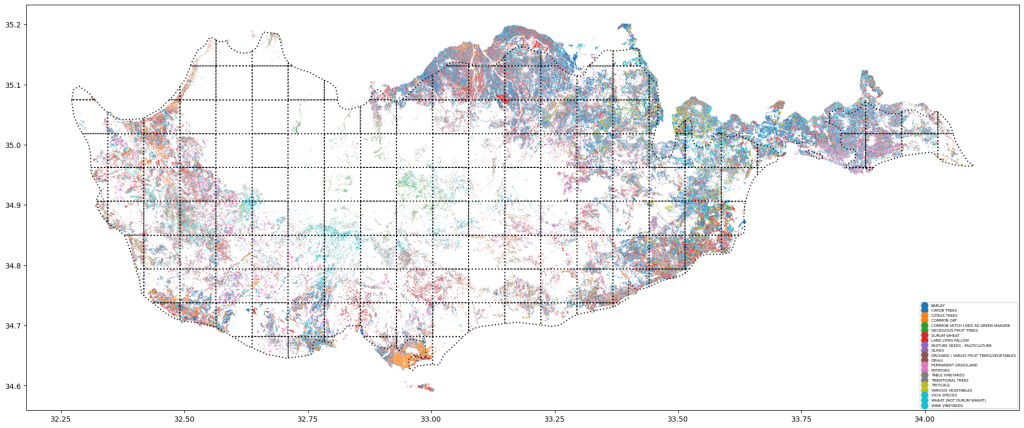
We recently had the opportunity to consult Eratosthenes CoE in efficiently managing and processing large geospatial datasets for crop classification. The project’s primary goal was to utilize Google Earth Engine (GEE) and Xarray to create and manage extensive datasets, crucial for their research.
The existing GEE Python libraries were insufficient for handling the volume and complexity of the required data. To address this, we recommended the use of Xee, an Xarray extension for GEE, which facilitates the creation of in-memory representations of large geospatial datasets.
Given the scale of the data, we recommended an implementation of Dask to parallelize the processing tasks. By leveraging Dask’s integration with Xarray, the efficient distribution of the computational load across our high-performance computing (HPC) cluster was enabled. This approach significantly reduced processing time and ensured that the project could handle the large datasets necessary for accurate crop classification.
The successful implementation of these solutions has provided Eratosthenes with a scalable and efficient data management pipeline, enhancing their research capabilities in the field of Earth Observation.